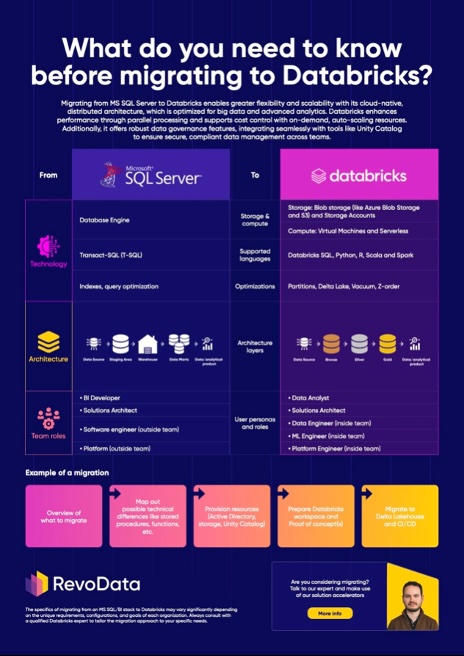
SQL Server vs Apache Spark: A Deep Dive into Execution Differences
The way SQL Server and Apache Spark (backbone of Databricks) process queries is fundamentally different, and understanding these differences is crucial when migrating or optimizing workloads. While SQL Server relies on a single-node, transaction-optimized execution engine, Spark in Databricks is built for distributed, parallel processing.
Execution Model: Single-Node vs. Distributed Processing
SQL Server executes queries within a single-node environment, meaning all operations—such as joins, aggregations, and filtering—occur on a centralized database server. The query optimizer determines the best execution plan, using indexes, statistics, and caching to improve efficiency. However, performance is ultimately limited by the resources (CPU, memory, and disk) of a single machine.
Databricks, powered by Apache Spark, distributes query execution across multiple nodes in a cluster. Instead of a single execution plan operating on one server, Spark breaks down queries into smaller tasks, which are executed in parallel across worker nodes. This approach enables Databricks to handle massive datasets efficiently, leveraging memory and compute resources across a distributed system.
Query Execution Breakdown
- SQL Server: A query is parsed, optimized into an execution plan, and executed on a single machine. It reads data from disk (or memory if cached), processes it using indexes and statistics, and returns results.
- Databricks (Spark): A query is parsed and transformed into a Directed Acyclic Graph (DAG), which is then broken down into stages and tasks. The Spark scheduler distributes these tasks across worker nodes, where computations are executed in memory as much as possible before writing results back to storage.
Data Shuffling and Joins
One of the biggest differences between the two systems is how they handle joins and aggregations.
- SQL Server: Since all data is processed on a single machine, joins rely heavily on indexes and sorting. If indexes are missing or inefficient, operations like hash joins or merge joins can cause expensive disk I/O.
- Databricks (Spark): Joins require shuffling, where data is redistributed across nodes to ensure matching keys are on the same worker. This introduces network overhead but allows for massive scalability. Techniques like broadcast joins (sending a small table to all nodes) help reduce shuffle costs and improve performance.
Caching and Storage Optimization
OptSQL Server relies on the buffer pool to cache frequently accessed data in memory, minimizing disk reads. Indexed data is stored efficiently on disk, and execution plans are cached for reuse.
Databricks, on the other hand, benefits from in-memory caching using Spark’s caching feature, reducing repeated reads from cloud storage (e.g., Azure Blob or AWS S3). Additionally, techniques like Z-ordering and partitioning help optimize data layout, reducing scan times for large datasets.
Fault Tolerance and Scalability
SQL Server operates with ACID transactions and high availability mechanisms like Always On Availability Groups, but it lacks inherent fault tolerance in query execution. If a process fails, it must restart.
Databricks, through Spark, provides fault tolerance via lineage and recomputation. If a node fails, Spark reruns only the affected tasks, ensuring resilience without manual intervention. Additionally, horizontal scalability allows it to scale dynamically based on workload demands.
Do you want to know more?
Are you considering migrating workloads from SQL Server to Databricks? Understanding execution models is key to designing efficient queries and avoiding performance pitfalls. Let’s connect and discuss how to make your transition seamless!

Rafal Frydrych
Senior Consultant at RevoData, sharing with you his knowledge in the opinionated series: Migrating from MSBI to Databricks.